With it’s simplicity of use and the elegance it provides, Vagrant proves to be an interesting tool for a security professional. In this article I’ll give a basic overview so that you can start using it. So what is exactly Vagrant? Think of it as a wrapper around your virtualization provider like VMware or Virtual Box. By using Vagrant you get greater control and flexibility in creating, and managing multiple virtual machines at the same time.
To understand better let’s take an use case. Imagine that you are building an IDS lab. You would typically require 3 machines – Server, Sensor and Monitoring machine. Now to create this setup in Virtual Box you need to perform a series of repetitive tasks - installing the operating system, applications, define networking etc. Once the setup is done, you need to bring up and manage these machines individually. All these activities kind of take your focus away from the core of what you might have wanted– like testing some Snort rules or understanding how Bro IDS works. Wouldn’t it be great if these repetitive tasks can be automated, so that you can focus on stuff that matters?
This is where Vagrant comes in. With Vagrant you simply write a configuration file to define these 3 machines. You can subsequently bring them up, install the OS, provision them and manage them using a handful of “vagrant” commands. So with Vagrant, you move from managing individual machines to managing an environment. Here’s a simple visualization of how Vagrant works:
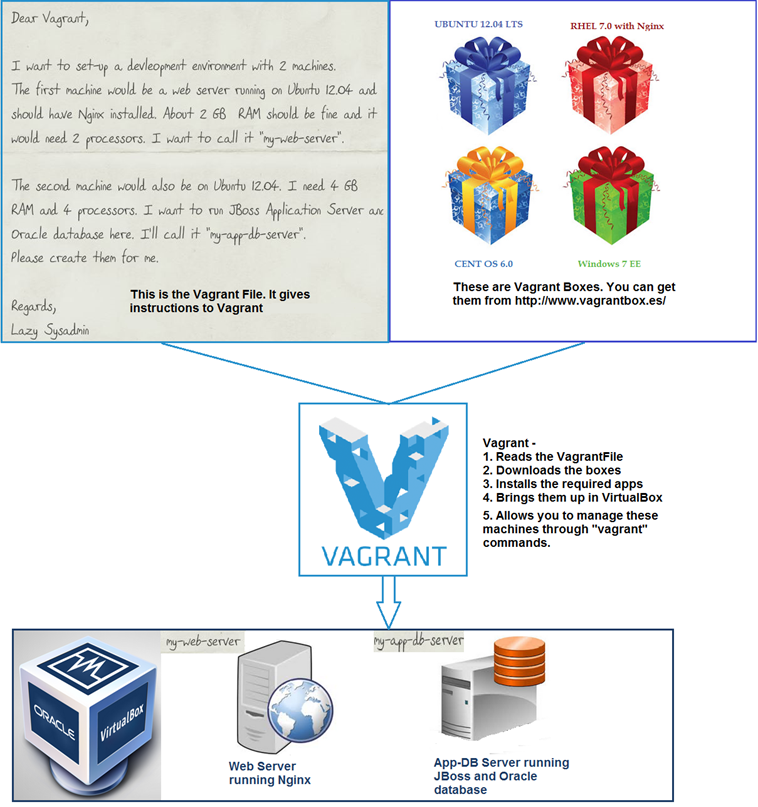
#1 - The VagrantFile |
| The VagrantFile is an ASCII based text file where you specify the configuration of the virtual machine you require. If you need 10 machines for your lab then you need to specify them sequentially in the VagrantFile.
Here is a snippet from the VagrantFile, to create a simple Ubuntu virtual machine. The syntax is based on Ruby. But even if you don’t know Ruby at all it is fairly straight to understand and implement. #- This line indicates the beginning of configuration. |
#2 – The Vagrant Boxes |
A box is file that represents a virtual machine. Think of it as an appliance that you can plug in to Vagrant and start running. Boxes are available for download from vagrantbox.es and the Hashicorp site. In addition to downloading boxes you can also create your own boxes and use them. |
#3 – Virtualization Providers |
This would typically be any software that provides an emulated environment for running different operating systems. Popular options are Vmware Player/Workstation/Fusion, and VirtualBox. Vagrant works free and fine with VirtualBox. However if you want to use it with VMware, you need to purchase additional licenses. |
#4 – The Vagrant Software |
The Vagrant software:
|
#5 – Plug-ins |
Vagrant provides extensibility with the use of Plug-ins (not shown in above diagram). As a developer you might be interested to add new vagrant commands, provide easier options to configure a host, add support for provisioners etc. In fact, Vagrant itself ships with a set of core plug-ins that work behind the scenes to configure and bring up your VM. You can find the list of core plug-ins here. Plug-ins are developed using Ruby and are implemented as self-contained packages (Rubygems). |
To know more about Vagrant refer the Vagrant documentation or the very readable book by Mitchell Hashimoto – Vagrant Up and Running.







